Nintex Best Practices: Naming variables
When developing applications using C# or JavaScript there are naming conventions for variables and other artifacts such as classes. This makes it easier to understand code from other developers.
But what about variables in a Nintex Workflow?
I often work on Nintex workflows developed by other people. I am regularly annoyed about the naming of the variables. The names of the variables are not consistent and the variable type is not apparent.
Let's take a look at the existing data types in Nintex varibals and then define a nomenclature:
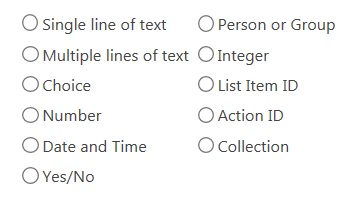
I often see that developers use var_ as a prefix in workflow variables, presumably to distinguish workflow variables from other artifacts. This may be useful, but it is more important to recognize the data type from the prefix. Here is the prefix I put in front of a variable:
| Nintex variable type | Prefix |
|
Single line of text |
txt |
|
Multiple line of text |
mul |
|
Choice |
cho |
|
Number |
num |
|
Date and Time |
dat |
|
Yes/no |
yn |
|
Person or Group |
peo |
|
Integer |
int |
|
List Item ID |
lid |
|
Action ID |
aid |
|
Collection |
col |
Next, I describe what the variable is intended for. As in C# or TypeScript I use camelCase. Let's assume that the variable stores the name of a sales person. If the variable is of type "person/group" I use pg_nameSales, if the variable is of type "text" I use txt_nameSales.
You prefer pgNameSales or var_pg_nameSales? It doesn't matter, but you should keep the naming consistent. This makes it much easier for other developers to understand your Nintex workflows. But it is also useful for you if you need to adjust the workflow after a long time.